
Brainwash Dataset
Brainwash is a dataset of livecam images taken from San Francisco's Brainwash Cafe. It includes 11,917 images of "everyday life of a busy downtown cafe" 1 captured at 100 second intervals throughout the day. The Brainwash dataset includes 3 full days of webcam images taken on October 27, November 13, and November 24 in 2014. According the author's research paper introducing the dataset, the images were acquired with the help of Angelcam.com. 2
The Brainwash dataset is unique because it uses images from a publicly available webcam that records people inside a privately owned business without their consent. No ordinary cafe customer could ever suspect that their image would end up in dataset used for surveillance research and development, but that is exactly what happened to customers at Brainwash Cafe in San Francisco.
Although Brainwash appears to be a less popular dataset, it was notably used in 2016 and 2017 by researchers affiliated with the National University of Defense Technology in China for two research projects on advancing the capabilities of object detection to more accurately isolate the target region in an image. 3 [military body, the Central Military Commission.
The Brainwash dataset also appears in a 2018 research paper affiliated with Megvii (Face++) that used images from Brainwash cafe "to validate the generalization ability of [their] CrowdHuman dataset for head detection." 5. Megvii is the parent company of Face++, who has provided surveillance technology to monitor Uighur Muslims in Xinjiang and may be blacklisted in the United States.
Updates
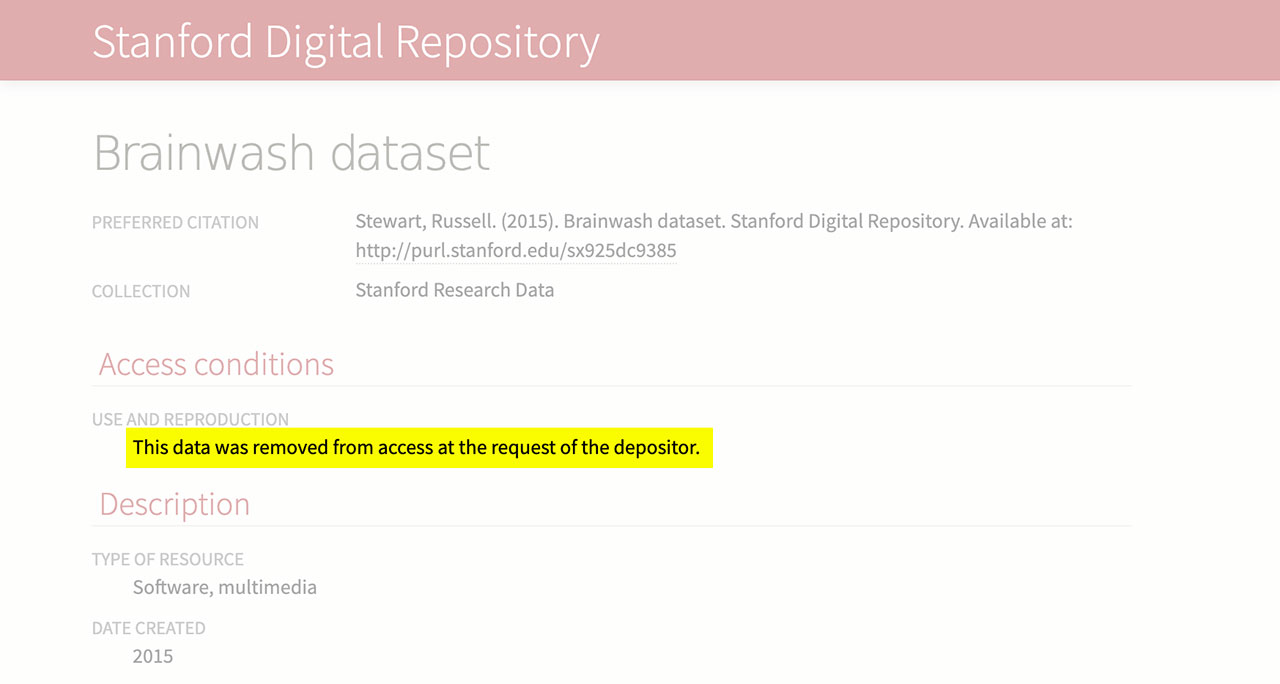
Since posting about this dataset and showing its connections to the National Unviversity of Defense Technology in China, the Brainwash dataset is no longer available for download. As of June 2, 2019 it has been "removed from access at the request of the depositor."
The two papers associated with the National University of Defense Technology in China have also been affected. The citations linking back to the Brainwash dataset paper no longer appear in the Semantic Scholar API search results. The citation references on the pages for NUDT citation 1 and NUDT citation 2 now display the text "Sorry, this paper is not in our corpus", no longer linking back to the original Brainwash paper, effectively censoring the NUDT connections from API search results.


Information Supply Chain
To help understand how Brainwash Dataset has been used around the world by commercial, military, and academic organizations; existing publicly available research citing Brainwash Dataset was collected, verified, and geocoded to show how AI training data has proliferated around the world. Click on the markers to reveal research projects at that location.
- Academic
- Commercial
- Military / Government

Press Coverage
- New York Times: Facial Recognition Tech Is Growing Stronger, Thanks to Your Face
- De Tijd: Brainwash
Citing This Work
If you reference or use any data from the Exposing.ai project, cite our original research as follows:
@online{Exposing.ai,
author = {Harvey, Adam},
title = {Exposing.ai},
year = 2021,
url = {https://exposing.ai},
urldate = {2021-01-01}
}
If you reference or use any data from Brainwash cite the author's work:
@article{Stewart2016EndtoEndPD,
author = "Stewart, R. and Andriluka, M. and Ng, A.",
title = "End-to-End People Detection in Crowded Scenes",
journal = "2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)",
year = "2016",
pages = "2325-2333"
}
References
- 1 a"readme.txt" https://exhibits.stanford.edu/data/catalog/sx925dc9385.
- 2 aR. Stewart, et al. "End-to-End People Detection in Crowded Scenes". 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2016): 2325-2333.
- 3 aYule Li, et al. "Localized region context and object feature fusion for people head detection". 2016 IEEE International Conference on Image Processing (ICIP). (2016): 594-598.
- 4 Xin Zhao, et al. "A Replacement Algorithm of Non-Maximum Suppression Base on Graph Clustering". (2017):
- 5 aShuai Shao, et al. "CrowdHuman: A Benchmark for Detecting Human in a Crowd". (2018):